深度学习笔记——使用 Keras 识别数字

深度学习经过最近几年的快速发展业界已经积累了不少工程化的最佳实践,本文通过现在比较流行的 Keras 框架对深度学习的通用工作流程进行了一次梳理。
Keras 简介
Keras 是一个较高层次的深度学习模型构建工具。它通过调用 TensorFlow、 Theano 等底层引擎完成基础运算,自身提供了简单易用的接口。相比于直接使用 TensorFlow 等框架,它的开发效率更高。
安装 Keras
Keras 是一个标准的 python 库,在安装有 python 的终端上运行如下指令即可:$ pip install keras
要想真正运行 Keras 还需要安装对应的底层引擎,如果是 TensorFlow 的话可以执行 pip install tensorflow 进行安装。
MNIST 数据集
MNIST 是一个手写数字图片的数据集,其拥有6万个可用于训练的样本及1万个测试样本,由于它被深度学习领域广泛引用被誉为该领域的Hello World数据集。之前写过一篇使用 Caffe 通过 MNIST 训练模型的介绍,这次通过 Keras 完成同样的工作,不同的是由于 Keras 的简洁易用会使整个过程更加明晰。
工作流程
获取要解决问题的数据集
数据集需要包含输入数据集和输出数据集两个部分,其次这些数据应该被划分为训练集和测试集。其中训练集中还应留出一小部分作为验证集,以备对不断调整的模型进行评估。MNIST 数据集可以直接从 Keras 中获取到:from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
加载的数据从网络下载,需要等待一段时间。可以看到数据集已经被分为训练和测试两部分了,验证集的划分后面再做。
数据预处理
由于深度学习模型都是基于张量来做的,原始数据需要格式化为张量。除此之外数据的取值范围应该尽可能一致,且波动范围小。MNIST 数据集的输入是 28 * 28 的格式,输出是0到9的数组,虽然已经满足张量格式,但还是需要依照具体的模型做适当调整。首先我们尝试使用简单的全连接层来构建模型,全连接层输入数据的格式为 2D 张量,因此输入数据集需要做对应的转化:train_images1 = train_images.reshape((60000, 28*28))
train_images1 = train_images1.astype('float32') / 255
test_images1 = test_images.reshape((10000, 28*28))
test_images1 = test_images1.astype('float32') / 255
上面除了把输入图片数据转换为 2D 格式之外还把数值范围缩小到了0到1之间。对于单标签多分类问题,模型最后一层通常使用 softmax 激活函数,因而输出数据也需要做相应调整已适应此激活函数:from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
构建模型
深度学习模型都是层构成的网络,层数越多模型的参数也就越多,参数越多模型所能学习的“知识”也就越多,但这并不意味着模型的容量越大越好,容量过大的模型容易造成过拟合(训练数据表现优异而测试数据表现糟糕),因为模型形成了针对训练数据的字典式映射,显然这种模型并不是所期望的。因此构建模型一般都是从相对较少的层开始,下面先使用两个全连接层构建网络:from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(28*28,)))
model.add(layers.Dense(10, activation='softmax'))
除了层级的搭建外,构建模型还需要选择验证损失的函数,优化器以及训练过程中需要关注的指标。损失函数的选择取决于问题的类型,对于单标签多分类问题一般使用 categorical_crossentropy;优化器大多数时候 rmsprop 都是合适的;关注的指标对于这个例子就是 accuracy:model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
训练模型
训练开始之前需要将训练集中留出一小部分作为验证集:train_images1_val = train_images1[:10000]
train_labels_val = train_labels[:10000]
partial_train_images1 = train_images1[10000:]
partial_train_labels = train_labels[10000:]
开始训练:history = model.fit(partial_train_images1, partial_train_labels, epochs=20, batch_size=512, validation_data=(train_images1_val, train_labels_val))
将精度结果以图表方式显示出来:import matplotlib.pyplot as plt
history_dict = history.history
val_acc_values = history_dict['val_acc']
acc_values = history_dict['acc']
epochs = range(1, len(acc_values) + 1)
plt.plot(epochs, acc_values, 'bo', label='Training acc')
plt.plot(epochs, val_acc_values, 'b', label='Validation acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()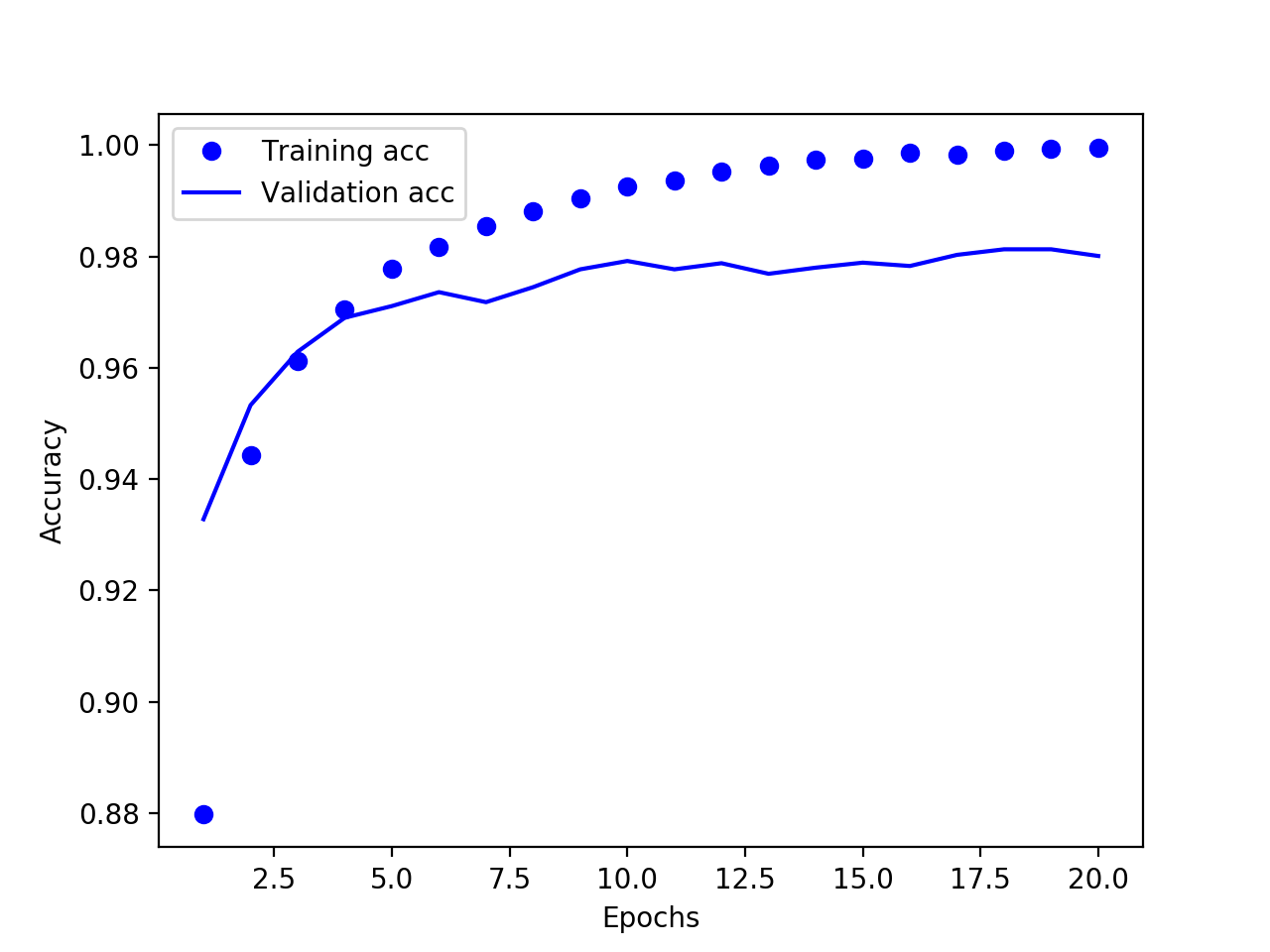
验证精度在第10轮达到了最高点 97.8%。下面在模型中添加一个二维卷积层看精度是否提高:model2 = models.Sequential()
model2.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)))
model2.add(layers.MaxPooling2D((2,2)))
model2.add(layers.Flatten())
model2.add(layers.Dense(512, activation='relu'))
model2.add(layers.Dense(10, activation='softmax'))
model2.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
现在的模型输入变成了4D张量,因而输入的训练数据格式也要做相应调整:train_images2 = train_images.reshape((60000, 28, 28, 1))
train_images2 = train_images2.astype('float32') / 255
test_images2 = test_images.reshape((10000, 28, 28, 1))
test_images2 = test_images2.astype('float32') / 255
train_images2_val = train_images2[:10000]
partial_train_images2 = train_images2[10000:]
重新训练:history = model2.fit(partial_train_images2, partial_train_labels, epochs=20, batch_size=512, validation_data=(train_images2_val, train_labels_val))
结束后打印精度的结果如下图: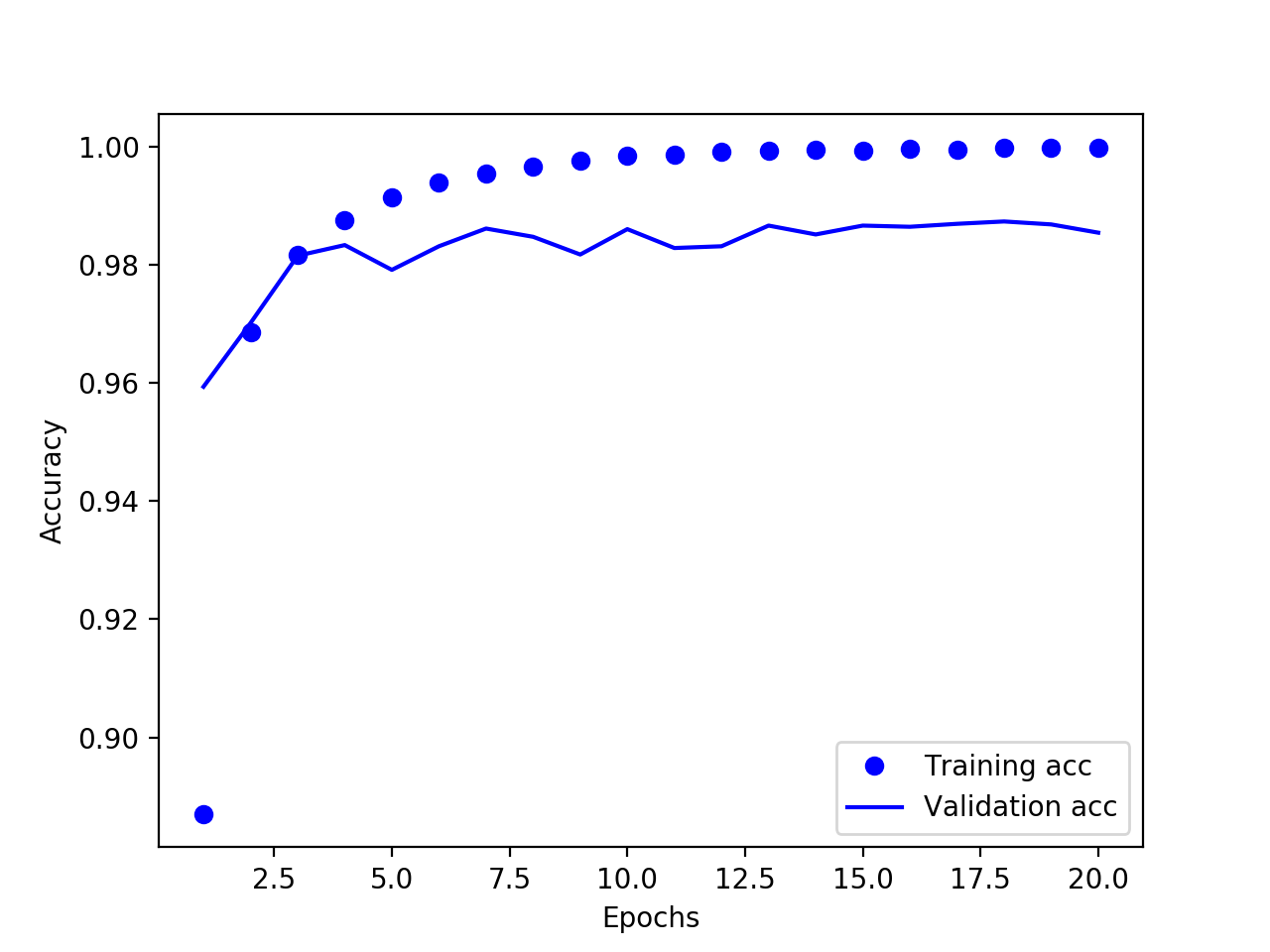
差不多在第4轮达到了最高点 98.2%,比之前提高了一些。继续添加卷积层然后重复上述步骤,结果见下列图表: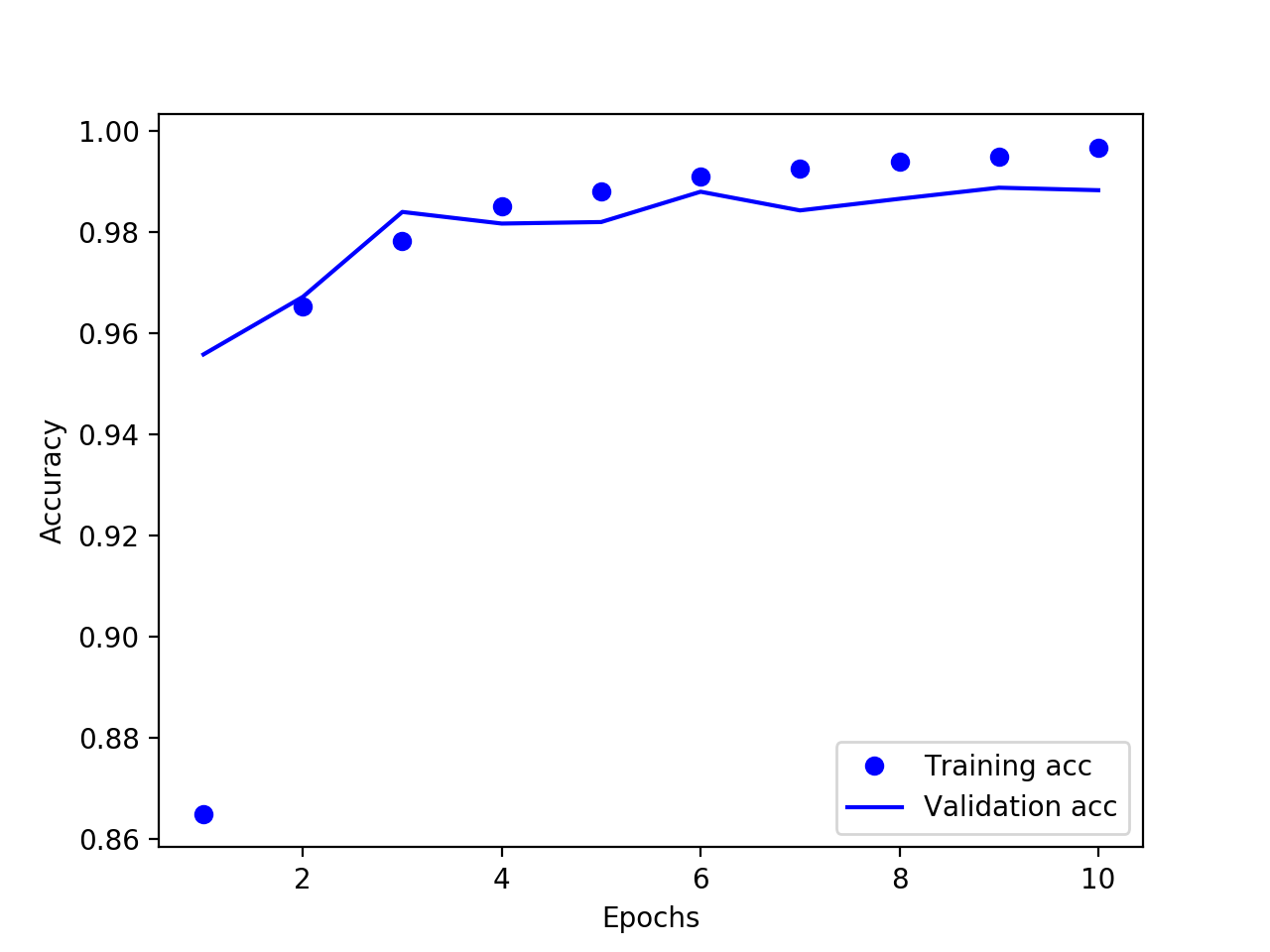
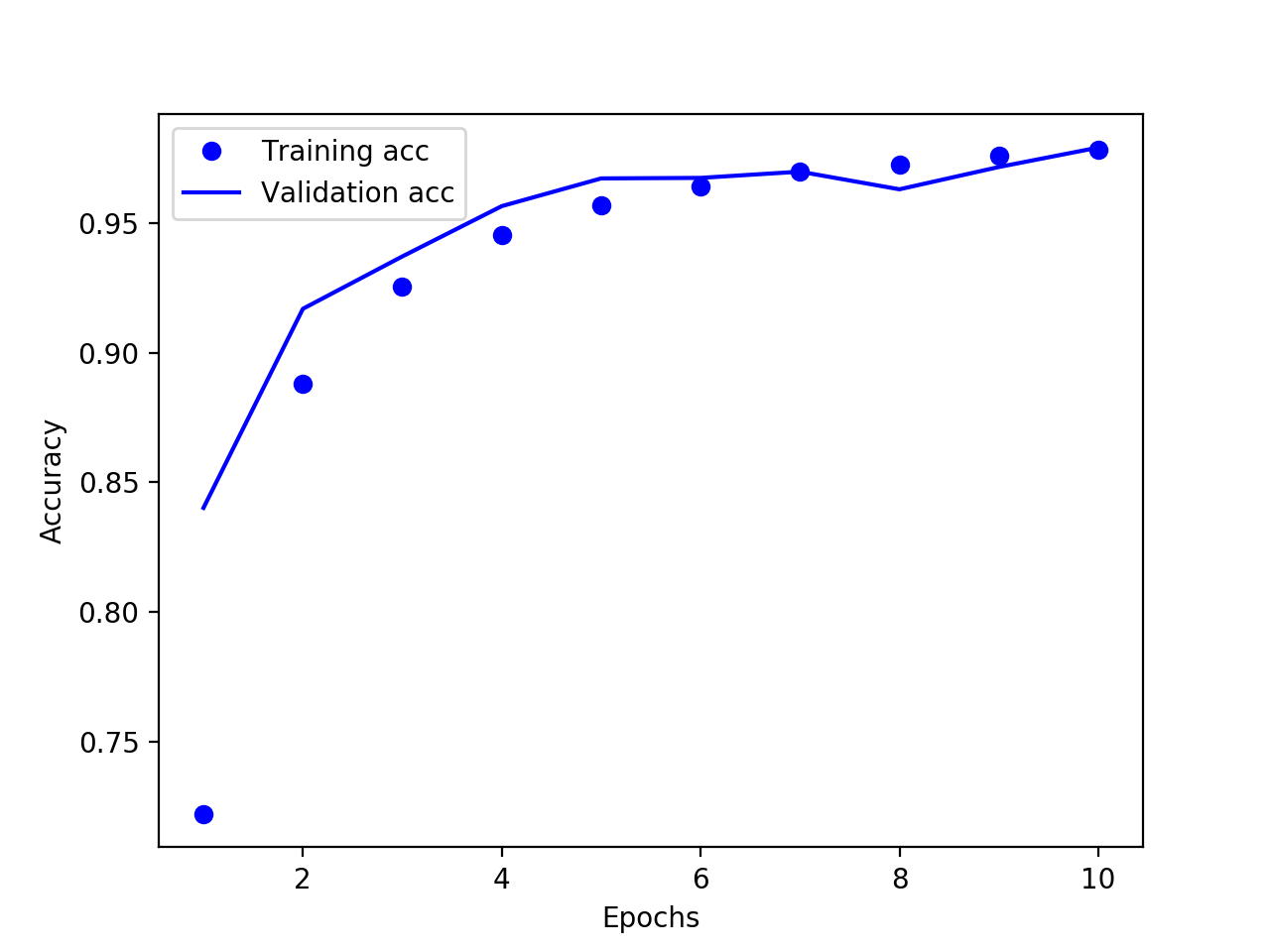
当加到第三卷积层时精度反而下降了,而且训练精度没有继续提升,说明模型可能已经欠拟合,此时可以降低每次梯度更新时的数据量 batch_size,让模型敏感度提高。这里将512调整为64,然后再次训练结果如下: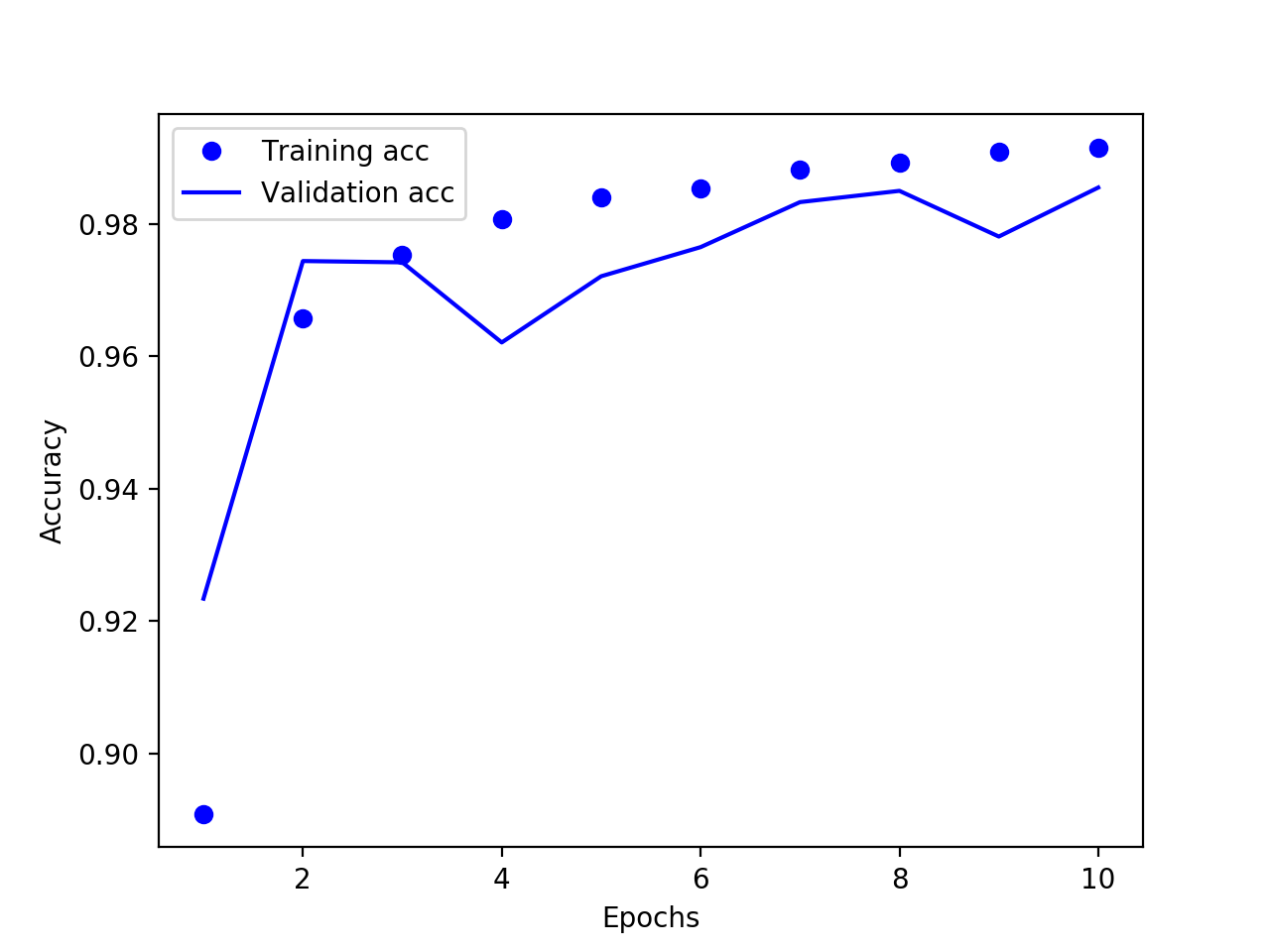
模型重新进入过拟合状态,但验证精度并没有提高(98.5%),只是恢复到了原来的水平,这时就需要近一步优化层的参数,加大卷积层的影响,降低全连接层的影响。这里通过增大卷积层的输出同时减小全连接层的输出来实现,新的模型定义如下:model2 = models.Sequential()
model2.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)))
model2.add(layers.MaxPooling2D((2,2)))
model2.add(layers.Conv2D(64, (3,3), activation='relu'))
model2.add(layers.MaxPooling2D((2,2)))
model2.add(layers.Conv2D(64, (3,3), activation='relu'))
model2.add(layers.MaxPooling2D((2,2)))
model2.add(layers.Flatten())
model2.add(layers.Dense(64, activation='relu'))
model2.add(layers.Dense(10, activation='softmax'))
model2.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
history = model2.fit(partial_train_images2, partial_train_labels, epochs=10, batch_size=64, validation_data=(train_images2_val, train_labels_val))
结果如下所示: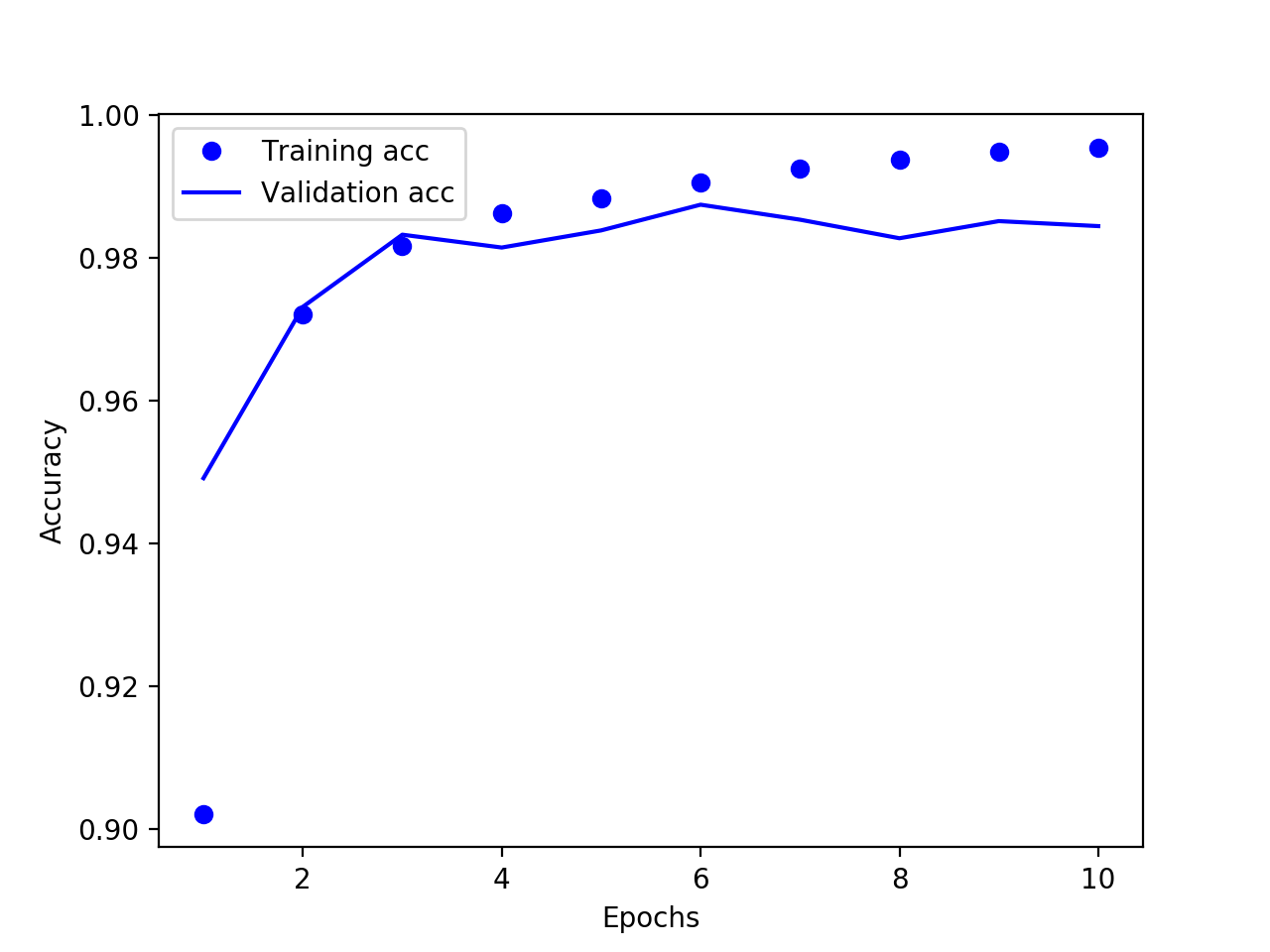
验证精度提升至98.7%,相对初始值已经提高不少。虽然模型精度已经很高,但仍处于过拟合状态,逻辑上仍有优化的空间,比如继续调整层的参数,添加 dropout,添加权重正则化,调整优化器的学习率等等。需要注意的是随着模型越来越复杂,训练的时间也会增加。
在测试集上进行最后评估
执行以下函数进行测试集评估:test_loss, test_acc = model2.evaluate(test_images2, test_labels)
测试集的精度为98.76%,和验证精度很接近。如果两者相差很大则说明验证数据集的选取有问题,数据集可能过小或不够随机,这种情况下可以考虑重复 K 折验证。