深度学习初探——使用Caffe识别手写数字

深度学习最近在计算机视觉、语音识别和自然语言处理等方面取得了不错的进展,成为目前机器学习领域热门的研究方向。本文结合深度学习框架 Caffe 从实践角度对深度学习理论进行一些初步地探索。
深度学习的优势
工业革命让人造机器取代人类完成了大部分的体力劳动,随着机器学习能力的不断提升人类有望可以将部分脑力劳动也交给机器完成。深度学习通过模拟生物神经网络来构建学习框架(人造神经网络),每个人造神经元使用激活函数来非线性地编码数据,不同层级的人造神经元间依靠权重值来传输数据,最终整个人造神经网络就会像人类的大脑一样拥有学习的能力(目前人造神经网络的复杂度还远不及生物,仅拥有很基本的学习能力)。深度学习可以让机器以目前最接近生物思考的方法进行运转,进而可能代替人类完成一部分脑力劳动。
深度学习跟传统的机器学习相比最大的优势在于不需要人工进行特征采集。传统的机器学习需要专业人士在特定数据中发现其特征,而深度学习能够通过算法自动完成这一过程,我们只需要构建一个通用的框架,然后提供数据和所想要的结果,最后通过不断地训练框架及优化其参数就可以获得具备某项能力的机器。
人造神经网络的构造
生物神经网络主要由很多神经元相互连接而成,人造神经网络也一样由人造神经元互联而成,如下图所示。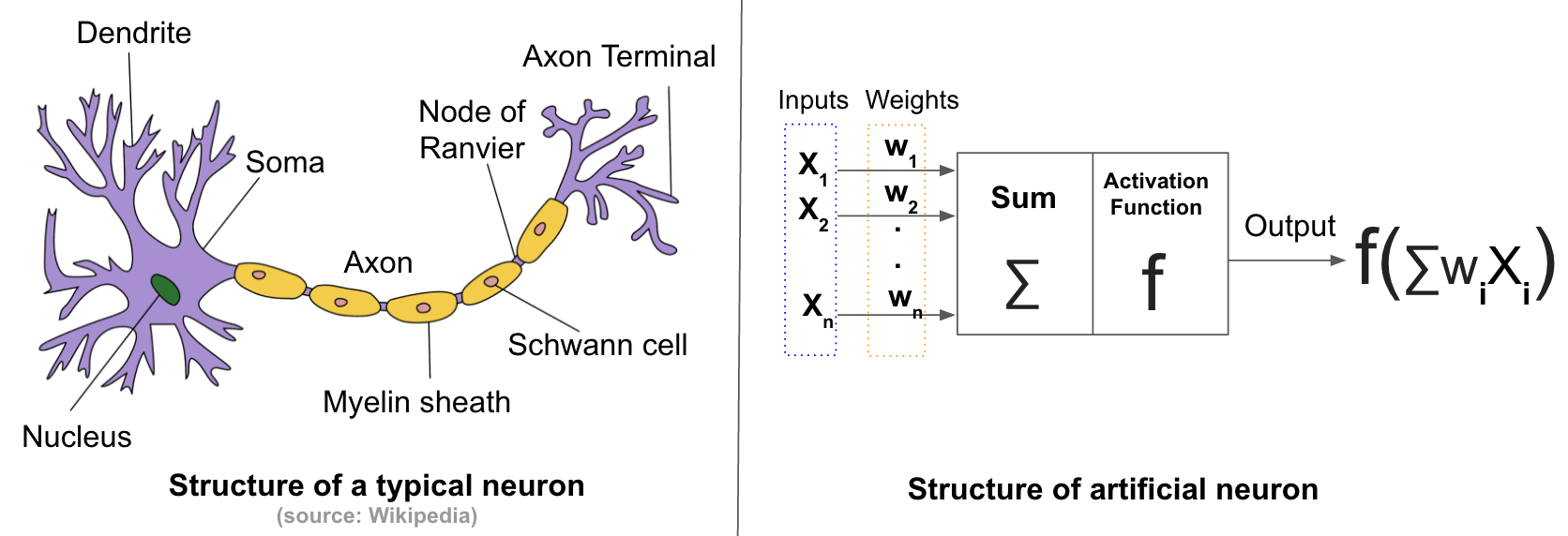
一个人造神经元有一定数量的输入接口,每个输入都拥有一个对应的权重值,数据通过输入进入后要通过一个激活函数才能输出,这个函数需要是非线性的(模拟生物神经元),常见的激活函数包括 Sigmoid, Tanh 以及 ReLU ,如下图所示,其中 ReLU 是深度学习中最常用的。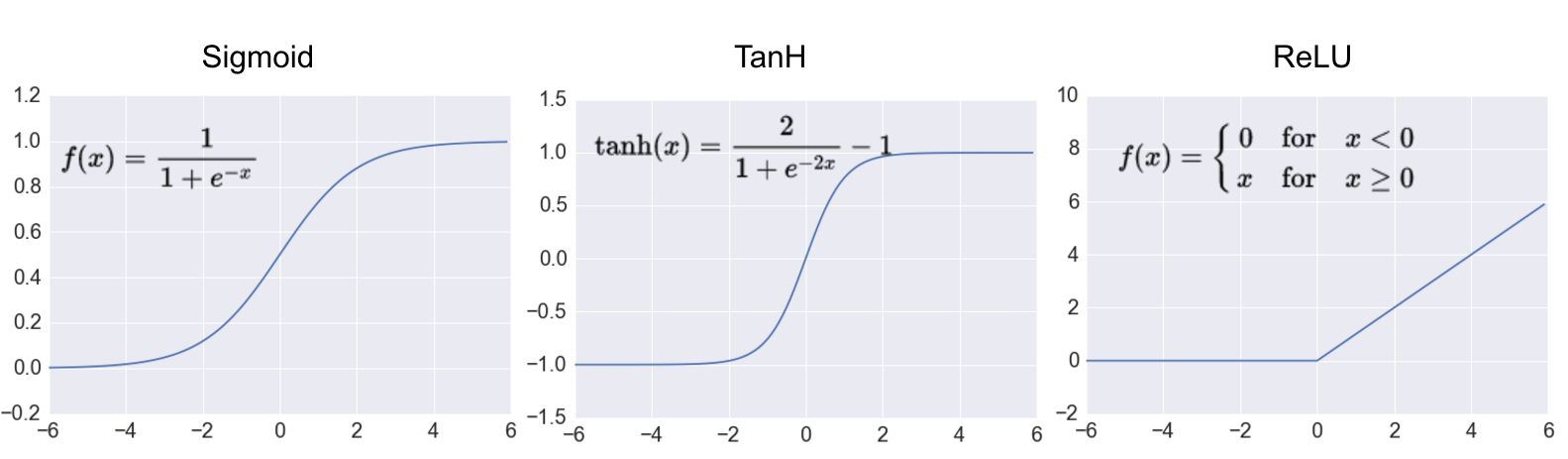
一个人造神经元的输出可能是另一个的输入,如此不断连接在一起便构成了人造神经网络,如下图所示。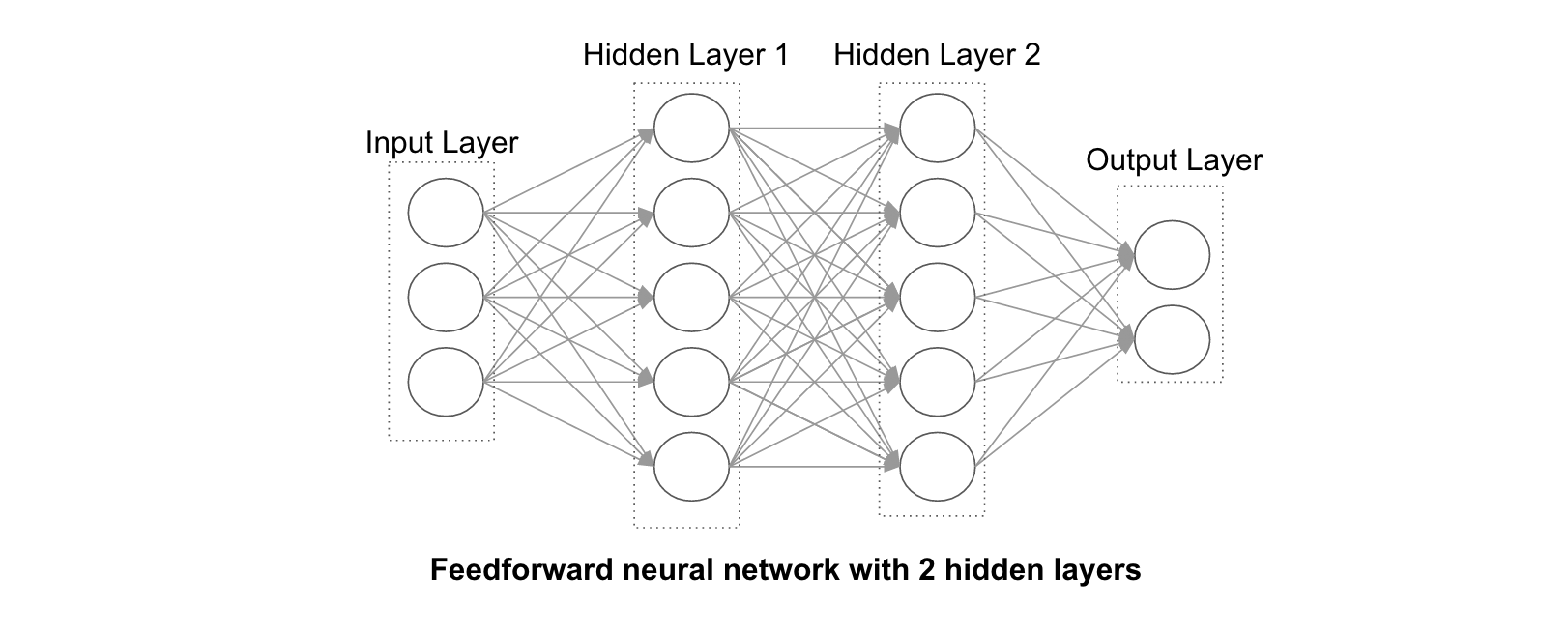
一个特定的人造神经网络可以解决一类特定的问题,要获得一个解决特定问题的人造神经网络需要使用相关数据对其进行训练,训练使用结合梯度检验的反向传导算法进行,详细的算法介绍可以看斯坦福的UFLDL教程。通过大量相关数据的训练人造神经元的权重值会越来越接近真实的范围,其人造神经网络也就越来越成熟。
实践
下面将使用深度学习框架 Caffe 结合一个入门级的计算机视觉数据集—— MNIST 来训练一个可以识别手写数字的人造神经网络。 Caffe 是一个比较流行的深度学习框架,使用它可以较容易的定义所需的人造神经网络,方便地调整相关的优化参数。 MNIST 是一个手写数字图片的数据集,其拥有6万个可用于训练的样本及1万个测试样本。
通过 Docker 获取 Caffe
DockerHub 上已有其他人做好的 Caffe 镜像,可直接使用:$ docker pull kaixhin/caffe
$ docker run -t kaixhin/caffe
该镜像基于 Ubuntu 14.04 制作,启动容器后即可通过 bash 进入容器:$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d890e55fa0e0 kaixhin/caffe "/bin/bash" 17 seconds ago Up 16 seconds romantic_rosalind
$ docker exec -ti d890e55fa0e0 /bin/bash
下载 MNIST
Caffe 已经包含了获取 MNIST 数据集的脚本,执行之后需要等待其下载完成:$ ./data/mnist/get_mnist.sh
然后还需要将网上获取到的 MNIST 数据集转换为 lmdb 格式, lmdb 是 Caffe 默认支持的一种数据库格式:$ ./examples/mnist/create_mnist.sh
由于 docker 中默认并不存在摄像头硬件,可能会看到Failed to initialize libdc1394错误,可以执行ln /dev/null /dev/raw1394来规避这个问题。
转换完成之后可以使用下面的脚本read_mnist_data.py查看这个数据集的内容:import sys
import lmdb
import argparse
sys.path.insert(0,"./python")
import numpy as np
import caffe
import textwrap
if __name__ == '__main__':
parse = argparse.ArgumentParser()
parse.add_argument('--lmdbpath')
args = parse.parse_args()
np.set_printoptions(linewidth=150)
env = lmdb.open(args.lmdbpath, readonly=True)
with env.begin() as txn:
cursor = txn.cursor()
i = 1
for key, value in cursor:
print 'key: ',key
datum = caffe.proto.caffe_pb2.Datum()
datum.ParseFromString(value)
flat_x = np.fromstring(datum.data, dtype=np.uint8)
x = flat_x.reshape(datum.channels, datum.height, datum.width)
y = datum.label
print 'x: '
for row in x[0]:
print row
print 'y: ',y
i = i + 1
if i > 10:
sys.exit(0)
上面的脚本会把数据集中前10行的信息显示在屏幕上,包括手写数字的图片和对应的标签,通过下面的命令运行这个脚本:$ python read_mnist_data.py --lmdbpath examples/mnist/mnist_train_lmdb
key: 00000000
x:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
y: 5
...
这个脚本需要依赖 python 库 lmdb ,如果运行出错尝试通过pip install lmdb解决。
进行训练
Caffe 也已经包含了训练识别 MNIST 的示例,它使用的是 LeNet 神经网络(一种比较简单的卷积神经网络),相关的设定都已经配置好,直接运行即可:$ ./examples/mnist/train_lenet.sh
这个 docker 版本的 caffe 仅支持使用 CPU 进行训练,如果遇到Cannot use GPU in CPU-only Caffe: check mode.错误需要将examples/mnist/lenet_solver.prototxt中的solver_mode: GPU修改为solver_mode: CPU。
识别手写数字的图片
等待一段时间后训练完成,之后便可用来识别手写的数字。
首先在一张白纸上使用黑笔写一个数字,然后使用照相机拍摄后传入电脑里,如下图:

由于 MNIST 中的训练数据都是黑底白字,所以需要使用图像处理软件将图片进行反色处理,处理之后的图片如下:
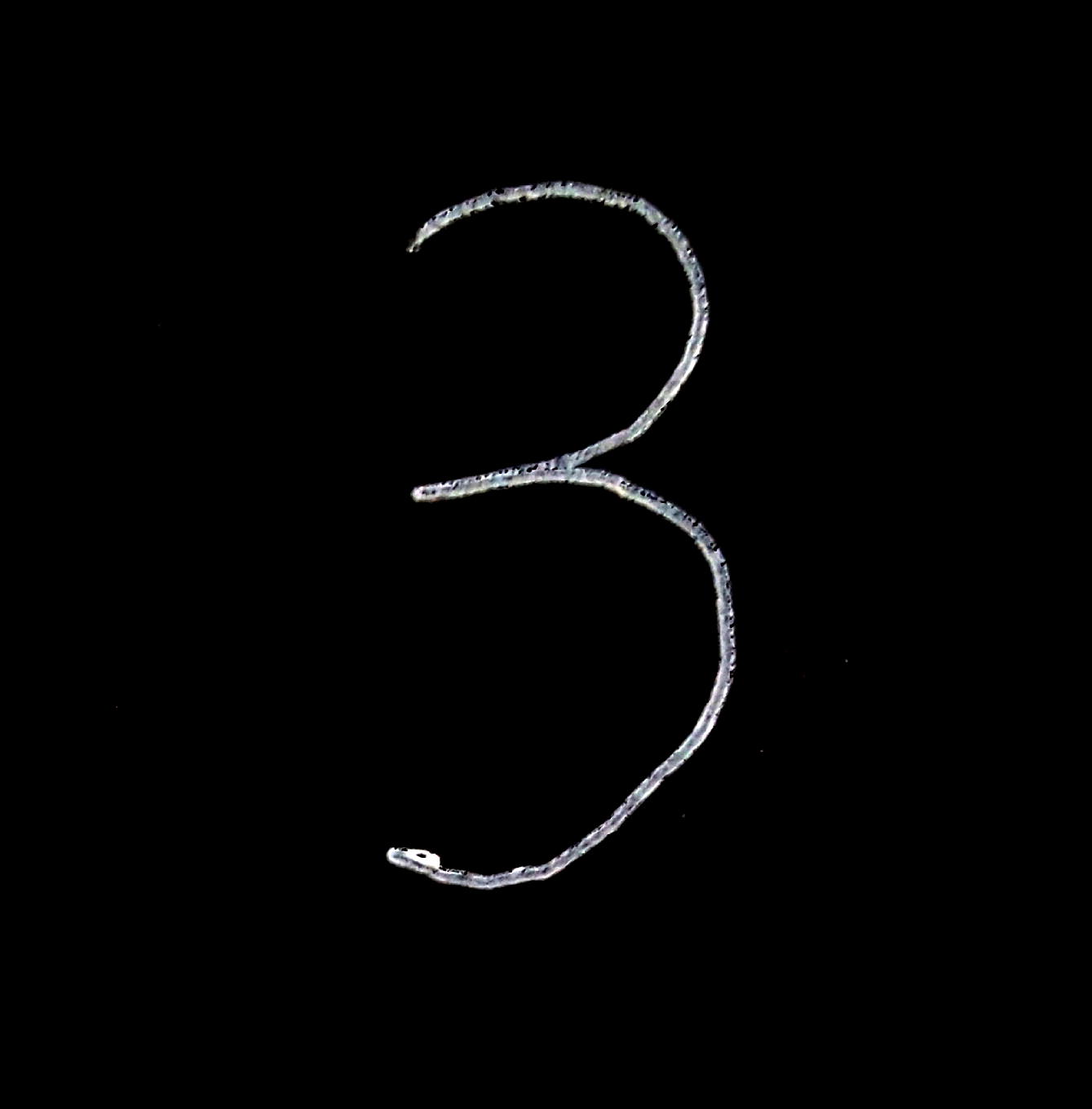
识别外部图片的神经网络输入和输出不同于训练的神经网络,需要将训练用的神经网络
examples/mnist/lenet_train_test.prototxt进行部分更改,在头部删除数据层,添加外部输入层,在尾部将层的类型改为Softmax,把文件重命名为examples/mnist/lenet_deploy.prototxt,其修改后的内容如下:name: "LeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}将图片复制到 caffe 所在的容器中,使用如下脚本
predict_png.py进行识别:import sys
import argparse
import cv2
sys.path.insert(0,"./python")
import caffe
def transform_img(img, img_width, img_height):
#Image Resizing
img = cv2.resize(img, (img_width, img_height), interpolation = cv2.INTER_CUBIC)
return img
if __name__ == '__main__':
parse = argparse.ArgumentParser()
parse.add_argument('--png')
args = parse.parse_args()
model = './examples/mnist/lenet_deploy.prototxt'
weights = './examples/mnist/lenet_iter_10000.caffemodel'
net = caffe.Net(model, weights, caffe.TEST)
img = cv2.imread(args.png, cv2.IMREAD_GRAYSCALE)
img = transform_img(img, 28, 28)
# print img
net.blobs['data'].data[...] = img
out = net.forward()
prob = out['prob'][0]
for index, item in enumerate(prob):
if item == 1:
print index通过下面的命令运行这个脚本:
$ python predict_png.py --png digit.png
...
3可以看到最终输出了正确的数字3,成功识别了图片中的手写数字。
如果遇到
No module named cv2错误,尝试apt-get install python-opencv。